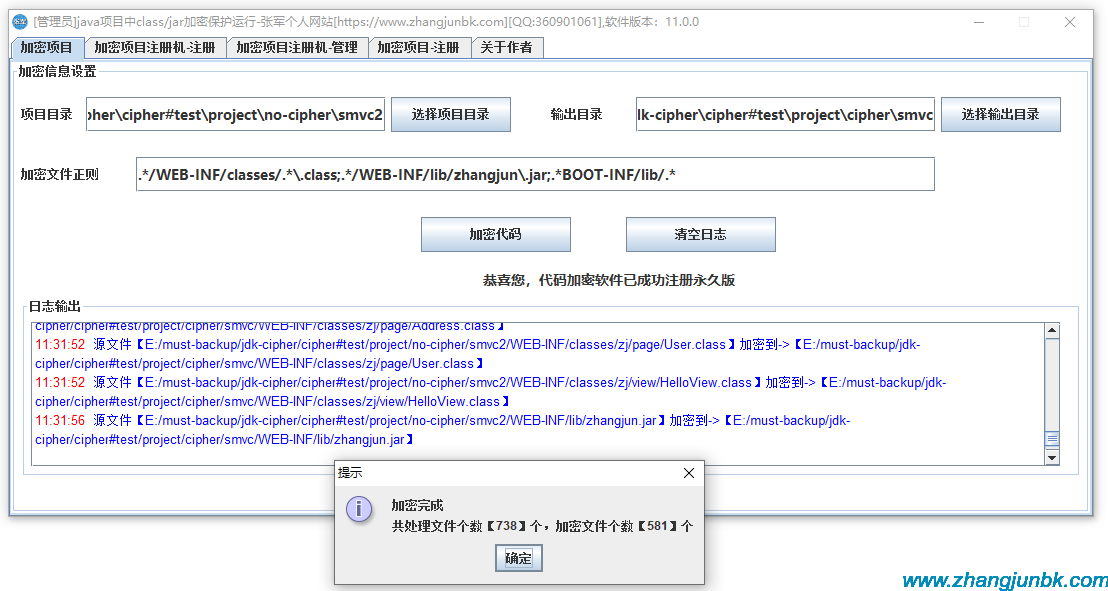
本文實例為大家分享了三種方式使用python寫數據到csv或xlsx文件,供大家參考,具體內容如下第一種:使用csv模塊,寫入到csv格式文件#-*-coding:utf-8-*-importcsvwithopen("my.csv","a",newline='')asf:writer=csv.writer(f)writer.writerow(["URL","predict","score"])row=[['1',1,1],['2',2,2],['3',3,
系統 2019-09-27 17:49:35 2156
今天小編再發一篇爬取電影的文章。不是小編懶,是小編真的不知道寫什么了,見諒。如果小編Get到新的技能,一定發。是不是有好多的小伙伴跟好久好久以前的小編一樣,看一個電影充個會員,這個沒關系,最主要的是,充一個平臺的VIP還不行得有好幾個才可以。這么貧窮的小編,當然只能看6分鐘的視頻了,不過沒關系,小編現在有python。不會小伙伴此刻的心情是:(如同所示)不過沒關系,小編接下來就是授教大家一些Python神技(零基礎的也是可以操作的奧)讓咱們首先來看看實現效
系統 2019-09-27 17:48:21 2156
count()方法返回obj出現在列表的次數。語法以下是count()方法的語法:list.count(obj)參數obj--這是在該列表被計數的對象。返回值此方法返回obj出現在列表的次數。例子下面的例子顯示了count()方法的使用。#!/usr/bin/pythonaList=[123,'xyz','zara','abc',123];print"Countfor123:",aList.count(123);print"Countforzara:",a
系統 2019-09-27 17:47:04 2156
組建一個關于書籍、作者、出版社的例子:fromdjango.dbimportmodelsclassPublisher(models.Model):name=models.CharField(max_length=30)address=models.CharField(max_length=50)city=models.CharField(max_length=60)state_province=models.CharField(max_length=30)
系統 2019-09-27 17:37:45 2156
這里主要講了bs4解析方法和json方法,以8684網頁為例子,爬取了全國公交線路importrequestsimporttimefrombs4importBeautifulSoupimportjsonfromxpinyinimportPinyinheaders={'User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/76.0.
系統 2019-09-27 17:53:12 2155
統計學習方法——樸素貝葉斯法原理1.樸素貝葉斯法的極大似然估計2.樸素貝葉斯極大似然學習及分類算法算法過程:2.Python實現defpriorProbability(labelList):#計算先驗概率labelSet=set(labelList)#得到類別的值labelCountDict={}#利用一個字典來存儲訓練集中各個類別的實例數forlabelinlabelList:iflabelnotinlabelCountDict:labelCountDi
系統 2019-09-27 17:50:19 2155
下面介紹在Linux上利用python獲取本機ip的方法.經過網上調查,發現大致有兩種方法,一種是調用shell腳本,另一種是利用python中的socket等模塊來得到,下面是這兩種方法的源碼:#!/usr/bin/envpython#encoding:utf-8#description:getlocalipaddressimportosimportsocket,fcntl,structdefget_ip():#注意外圍使用雙引號而非單引號,并且假設默認
系統 2019-09-27 17:50:19 2155
當前在線廣告服務中,廣告的點擊率(CTR)是評估廣告效果的一個非常重要的指標。因此,點擊率預測系統是必不可少的,并廣泛用于贊助搜索和實時出價。那么如何計算廣告的點擊率呢?廣告的點擊率=廣告點擊量/廣告的展現量如果一個廣告被展現了100次,其中被點擊了20次,那么點擊率就是20%。今天我們就來動手開發一個移動廣告點擊率的預測系統,我們數據來自于kaggle,數據包含了10天的Avazu的廣告點擊數據。數據你可以在這里下載移動廣告點擊數據,由于總數據量達到了4
系統 2019-09-27 17:48:59 2155
一、模擬登錄圖書館管理系統我們可以先看一下登錄頁面(很多學校這些管理系統頁面就是很low):兩種方式去模擬登錄圖書館:1.構造登錄表單進行模擬登錄這種方式模擬登錄似乎是很可靠的,但有時候就是在驗證碼獲取上很困難,如果簡單的網站,有的會利用當前時間戳來構造驗證碼,這種就很容易從網頁上觀察出來,但比如我們這次要模擬登錄的網站似乎是不能這樣做,因為它是使用JavaScript標準庫里的Math函數直接隨機生成的驗證碼鏈接,可以從下面圖片上觀察驗證碼處的代碼:它使
系統 2019-09-27 17:37:46 2155
簡介提到爬蟲,大部分人都會想到使用Scrapy工具,但是僅僅停留在會使用的階段。為了增加對爬蟲機制的理解,我們可以手動實現多線程的爬蟲過程,同時,引入IP代理池進行基本的反爬操作。本次使用天天基金網進行爬蟲,該網站具有反爬機制,同時數量足夠大,多線程效果較為明顯。技術路線IP代理池多線程爬蟲與反爬編寫思路首先,開始分析天天基金網的一些數據。經過抓包分析,可知:./fundcode_search.js包含所有基金的數據,同時,該地址具有反爬機制,多次訪問將會
系統 2019-09-27 17:57:51 2154
冒泡排序是一個排序算法。這個算法的名字由來是因為越大的元素會經由交換慢慢“浮”到數列的頂端。其核心是:重復地走訪過要排序的數列,一次比較兩個元素,如果他們的順序錯誤就把他們交換過來。走訪數列的工作是重復地進行直到沒有再需要交換,也就是說該數列已經排序完成。應用場景:小規模數據排序,隊列從小到大排序實例:將下列列表從小到大進行排序List=[1,5,7,4,9]foriinrange(0,4):forjinrange(0,4-i):ifList[j]>Lis
系統 2019-09-27 17:55:44 2154
這是書籍《PandasCookbook》書籍第06章的代碼復現,所有代碼運行在JupyterNotebook上,原講解地址是:https://www.jianshu.com/p/ab55e07418af我上傳代碼的github地址是:https://github.com/Asunqingwen/PandasCookbook.gitgithub上有該書中用到的data,里面代碼會不定期更新(因為工作原因,時間不定),直到本書學習完成!相比原講解,會穿插一些自
系統 2019-09-27 17:50:08 2154
這里介紹一個nii文件保存為png格式的方法。這篇文章是介紹多個nii文件保存為png格式的方法:https://www.jb51.net/article/165692.htm系統:Ubuntu16.04軟件:python3.5先用pip安裝nibabel、numpy、imageio、os。importnibabelasnibimportnumpyasnpimportimageioimportosdefread_niifile(niifile):#讀取ni
系統 2019-09-27 17:49:23 2154
下表列出了所有Python語言支持的比較操作符。假設變量a持有10和變量b持有20,則:例如:試試下面的例子就明白了所有的Python編程語言提供的比較操作符:#!/usr/bin/pythona=21b=10c=0if(a==b):print"Line1-aisequaltob"else:print"Line1-aisnotequaltob"if(a!=b):print"Line2-aisnotequaltob"else:print"Line2-aise
系統 2019-09-27 17:38:12 2154
我一直使用Python,用它處理各種數據科學項目。Python以易用聞名。有編碼經驗者學習數天就能上手(或有效使用它)。聽起來很不錯,不過,如果你既用Python,同時也是用其他語言,比如說C的話,或許會存在一些問題。給你舉個我自己經歷的例子吧。我精通命令式語言,如C和C++。對古老經典的語言如Lisp和Prolog能熟練使用。另外,我也用過Java,Javascript和PHP一段時間。(那么,學習)Python對我來講不是很簡單嗎?事實上,只是看起來容
系統 2019-09-27 17:37:35 2154