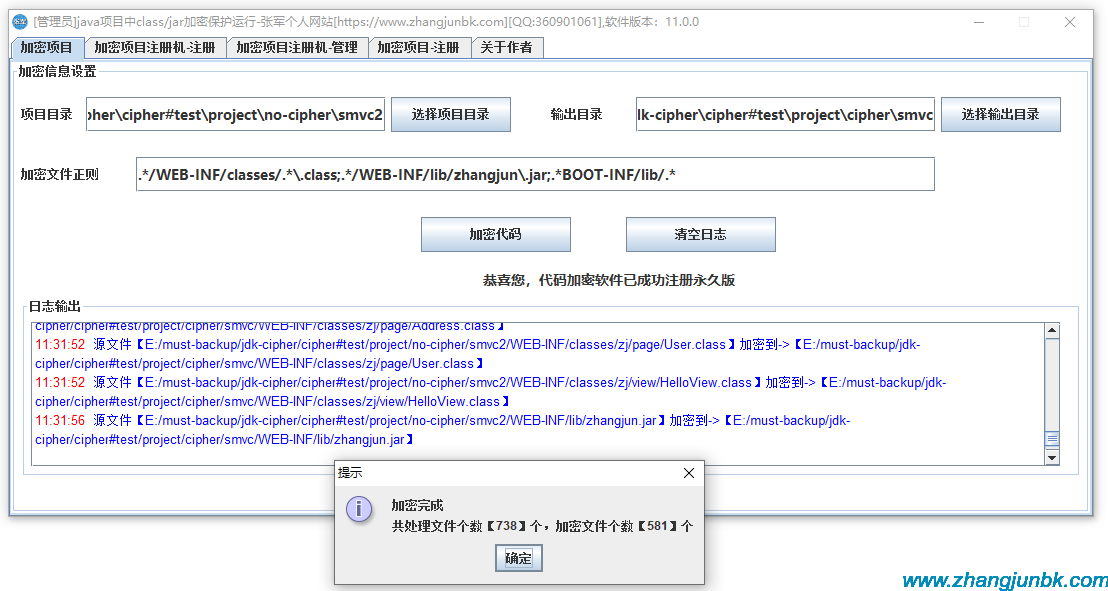
具體代碼如下所示:importsmtplib,email,os,timefromemail.mime.multipartimportMIMEMultipartfromemail.mime.textimportMIMETextfromemail.headerimportHeader#設置smtplib所需的參數(shù)smtpserver='smtp.qq.com'#SMTP服務器地址username='xxx@qq.com'#發(fā)件人地址,通過控制臺創(chuàng)建的發(fā)件人地址
系統(tǒng) 2019-09-27 17:49:18 1689
占位符,顧名思義就是插在輸出里站位的符號。占位符是絕大部分編程語言都存在的語法,而且大部分都是相通的,它是一種非常常用的字符串格式化的方式。1、常用占位符的含義s:獲取傳入對象的__str__方法的返回值,并將其格式化到指定位置r:獲取傳入對象的__repr__方法的返回值,并將其格式化到指定位置c:整數(shù):將數(shù)字轉換成其unicode對應的值,10進制范圍為0<=i<=1114111(py27則只支持0-255);字符:將字符添加到指定位置o:將整數(shù)轉換成
系統(tǒng) 2019-09-27 17:49:18 1689
一、字符串基本操作索引、切片、乘法、成員資格檢查、長度、長度、最小值、最大值字符串不可變,因此元素賦值和切片賦值是非法的、二、設置字符串的格式>>>"{3}{0}{2}{1}{3}{0}".format("be","not","or","to")'tobeornottobe'三設置字符串長度>>>"{foo}{}{bar}{}".format(1,2,bar=4,foo=3)'3142'>>>"{foo}{1}{bar}{0}".format(1,2,ba
系統(tǒng) 2019-09-27 17:49:14 1689
第一步:標記化處理表達式的第一步就是將其轉化為包含一個個獨立符號的列表。這一步很簡單,且不是本文的重點,因此在此處我省略了很多。首先,我定義了一些標記(數(shù)字不在此中,它們是默認的標記)和一個標記類型:token_map={'+':'ADD','-':'ADD','*':'MUL','/':'MUL','(':'LPAR',')':'RPAR'}Token=namedtuple('Token',['name','value'])下面就是我用來標記`expr`
系統(tǒng) 2019-09-27 17:49:09 1689
簡介在這篇文章中,我將向大家演示怎樣向一個通用計算器一樣解析并計算一個四則運算表達式。當我們結束的時候,我們將得到一個可以處理諸如1+2*-(-3+2)/5.6+3樣式的表達式的計算器了。當然,你也可以將它拓展的更為強大。我本意是想提供一個簡單有趣的課程來講解語法分析和正規(guī)語法(編譯原理內容)。同時,介紹一下PlyPlus,這是一個我斷斷續(xù)續(xù)改進了好幾年的語法解析接口。作為這個課程的附加產物,我們最后會得到完全可替代eval()的一個安全的四則運算器。如果
系統(tǒng) 2019-09-27 17:49:09 1689
1.在一個二維數(shù)組中(每個一維數(shù)組的長度相同),每一行都按照從左到右遞增的順序排序,每一列都按照從上到下遞增的順序排序。請完成一個函數(shù),輸入這樣的一個二維數(shù)組和一個整數(shù),判斷數(shù)組中是否含有該整數(shù)。思路:判斷數(shù)組中是否有該整數(shù),因此返回值為false或true。定義查詢函數(shù)Find(),使用循環(huán)判斷輸入的整數(shù)是否在array中,設置flag位,若含有則返回true,否則返回false。/*判斷整數(shù)是否在二維數(shù)組里*/classSolution:#array二
系統(tǒng) 2019-09-27 17:48:58 1689
【摘要】本節(jié)中,我們看一下正則表達式的相關用法。正則表達式是處理字符串的強大工具,它有自己特定的語法結構,有了它,實現(xiàn)字符串的檢索、替換、匹配驗證都不在話下。當然,對于爬蟲來說,有了它,從HTML里提取想要的信息就非常方便了。1.實例引入說了這么多,可能我們對它到底是個什么還是比較模糊,下面就用幾個實例來看一下正則表達式的用法。打開開源中國提供的正則表達式測試工具http://tool.oschina.net/regex/,輸入待匹配的文本,然后選擇常用的
系統(tǒng) 2019-09-27 17:48:57 1689
前面介紹過vSQLAlchemy中的Engine和Connection,這兩個對象用在rowSQL(原生的sql語句)上操作,而ORM(ObjectRelationalMapper)則是一種用面向對象的思維來操作表數(shù)據的技術。所謂ORM就是Python對象到數(shù)據表的一種映射關系。以前SQLAlchemy是怎么把Python對象和數(shù)據庫中表里面的每條記錄進行映射的呢?通過一個mapping函數(shù)先來看個例子:fromsqlalchemyimportTable,
系統(tǒng) 2019-09-27 17:48:55 1689
實例一:讀取txt文件中含有中文的字符importre##此處使用的編輯器是python3.xd="[\u4e00-\u9fa5]+"#中文匹配的符號f=open('test.txt','rb')#這里以二進制讀取,方便中文的轉義,不設置回報錯這里的TXT文檔#文檔內容:HelloworldChina你好,你好好ThisisatxtFiles2f程序員雜志一2d3程序員雜志二2d3程序員雜志三2d3程序員雜志四2d3#此處涉及到文本的讀取工作,先讀取文件,
系統(tǒng) 2019-09-27 17:48:50 1689
下面通過幾個案例來分析一下,注意:本節(jié)的parsematch函數(shù)請參考《妙用re.sub分析正則表達式解析匹配過程》案例一:>>>re.findall(r".*.*(.*)",'第二回悟徹菩提真妙理斷魔歸本合元神')['斷魔歸本合元神']>>>parsematch(r".*.*(.*)",'第二回悟徹菩提真妙理斷魔歸本合元神')第1次匹配,匹配情況:匹配子串group(0):第二回悟徹菩提真妙理斷魔歸本合元神,位置為:(0,19)匹配子串group(1):
系統(tǒng) 2019-09-27 17:48:48 1689